딥러닝 주요 논문 리뷰 시리즈 Deep learning milestone papers review series
통계 공부에 이어 또 캐글 예제나 풀어볼까 하다가, 다시 초심으로 돌아가자는 마음에 딥러닝의 주요 논문들을 뽑아서 읽어보기로 했습니다. GitHub과 웹사이트에서 Arxiv 논문을 찾아, 읽는 김에 요약도 해보기로 했습니다. 자세히 읽지는 않았으니 정확하지 않거나 핵심이 아닌 부분이 있을 수도 있고, 모든 딥러닝의 주요 논문이 있지도 않습니다. 혹시 공부하시다가 놓친 부분을 제 글에서 다시 잡으실 수라도 있으면 저는 뿌듯하겠습니다.
네번째 글은 이미지 생성모델에 대한 논문들입니다. 자연어 생성모델처럼, 이미지 생성모델은 기존 머신러닝 방법론으로는 한계가 있어 이를 딥러닝으로 극복해나가고 있습니다. 특히 최근 Stable Diffusion으로 화제가 되고 있는 분야입니다. 머신러닝이나 딥러닝 기초를 학습하시고 싶은 분들은 단단한 머신러닝 또는 심층 학습 같은 교과서를 먼저 읽고 오시면 좋습니다.
1. VAE (Variational Auto Encoder)

- Kingma, D. P., & Welling, M. (2013). Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114.
- 어떻게 새로운 이미지를 기존 features를 재조합해 생성할지에 대한 연구를 해봄.
- 생성모델이란 베이즈모델이 아닐까? 사실 학습하고자 하는 데이터도 기존에 있던 분포에서 나온 거니까, 데이터로 분포를 다시 구하는건 베이즈모델임.
- 여러개의 신경망에 학습데이터로 기존 정규분포를 추정한뒤 랜덤하게 오차를 더해 샘플링한 다음, 학습데이터와의 cross-entropy를 구해 역전파해주며 학습함.
- 따라서 따로 label이 없이 데이터에 variation만 주면서 학습한 unsupervised learning임.
- 딥러닝이라기보단 기존의 통계적 머신러닝에서 신경망을 살짝 활용한 쪽에 가까움.
2. GAN (Generative Adversarial Networks)
- Goodfellow, I., et al. (2014). Generative adversarial networks. arXiv preprint arXiv:1406:2661.
- Maximum likelihood나 Markov chain 등의 개념을 사용하지 않음.
- 생성모델과 분류모델을 동시에 만들어 경쟁적으로 학습시킴.
- 생성모델은 학습데이터에 근거해 알고자 하는 모분포를 학습해 노이즈가 섞인 유사 데이터를 내뱉는 평범한 신경망이고, 분류모델은 원 학습데이터와 생성모델의 결과데이터를 둘다 학습데이터 삼아 원 학습데이터를 구별해내는 신경망임.
- 이 때, 분류모델은 학습데이터는 학습데이터로, 생성모델의 결과데이터는 만들어진 결과데이터로 분류되게끔 학습하고, 생성모델은 분류모델의 정확도가 떨어지게끔 학습함.
- 즉 분류모델은 생성모델이 만든 데이터가 진짜 학습데이터가 맞는지 찾고, 생성모델은 분류모델이 학습데이터로 오해할만큼의 데이터를 만들게끔 적대적으로 학습하는 것임.
- 처음에는 분류모델이 쉽게 생성모델이 만들어낸 데이터를 구분하겠지만, 이 확률을 최소화하는 방향으로 생성모델이 최적화될 수록 분류모델이 이를 구분하기 힘들어짐.
3. StyleGAN

- Karras, T., Laine, S., & Aila, T. (2019). A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition.
- Transfer learning과 비슷하게, 한 입력데이터에서 읽은 스타일만 각 layer에 반복적으로 적용시켜 유사 이미지를 만들어냄.
- Fully-connected layer를 몇 번 통과한 latent feature를 생성모델의 중간에 adaptive instance normalization, 즉 정규화 및 변환해서 갖다박아버림.
- 중간에 noise를 몇 번 섞어주는 것까지만 하면 되는 아주 간단한 모델.
4. StableDiffusion
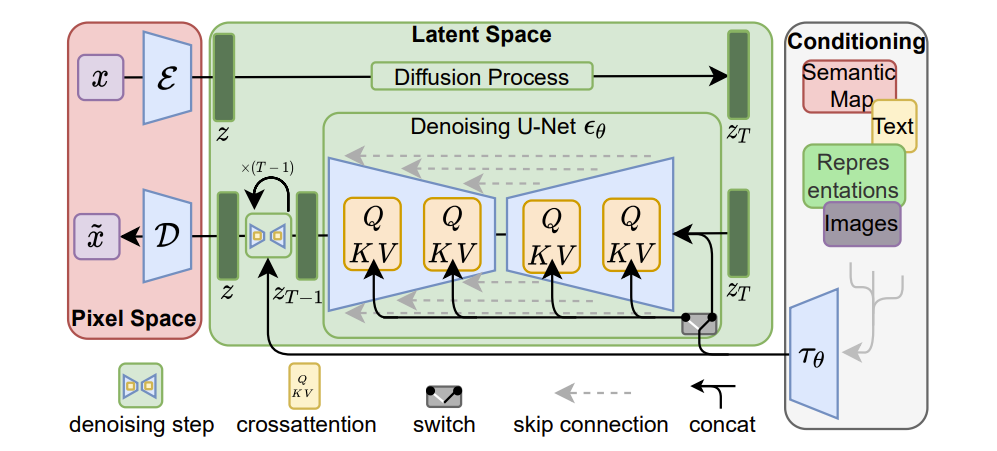
- Rombach, R., Blattmann, A., Lorenz, D., Esser, P., & Ommer, B. (2022). High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.
- 원래 이름은 latent diffusion. 논문 엄청 어려움.
- 기존 모델들은 너무 복잡하고 계산에 자원과 시간도 너무 많이 필요하며 압축을 하기 때문에 고해상도의 이미지를 저해상도로 변환해야함.
- 이미지는 원래 perceptual compression, 즉 detail을 제거하지만 아직 각 요소가 갖는 의미는 해석하지 못하는 단계, 그리고 semantic compression, 즉 모델이 요소가 갖는 의미를 해석하는 단계로 이루어진다고 봄.
- Perceptual compression 단계에서 의미를 모른채로 detail을 마구 제거해버리면 RNN마냥 꼭 필요한 요소를 뒤에서 학습할 기회조차 안 생길 수도 있음.
- Latent diffusion이란 semantic compression만 활용, diffusion, 즉 noise를 줘서 만들어낸 결과값에 대해 markov chain을 적용해 그 전 state를 U-Net이란 attention model로 추측하는데, 최종적으로 noise가 제거된 학습데이터를 만드는 것이 목적임.
- 학습된 모델은 text나 image가 input으로 주어지더라도 임의의 noise 속에서 해당 text나 image가 원하는 학습데이터를 역으로 추론할 수 있음.
- 따라서 압축이 적기 때문에 아키텍처가 단순하고 가볍고 빠르며 고해상도의 이미지를 처리 가능함.
'과학 > 머신러닝' 카테고리의 다른 글
| 딥러닝 주요 논문 리뷰 (3) - 이미지 (0) | 2022.12.10 |
|---|---|
| 딥러닝 주요 논문 리뷰 (2) - 자연어 생성 (0) | 2022.12.04 |
| 딥러닝 주요 논문 리뷰 (1) - 자연어 (0) | 2022.11.26 |
| 딥러닝 주요 논문 리뷰 (0) - 기초 (0) | 2022.11.21 |




댓글