딥러닝 주요 논문 리뷰 시리즈 Deep learning milestone papers review series
통계 공부에 이어 또 캐글 예제나 풀어볼까 하다가, 다시 초심으로 돌아가자는 마음에 딥러닝의 주요 논문들을 뽑아서 읽어보기로 했습니다. GitHub과 웹사이트에서 Arxiv 논문을 찾아, 읽는 김에 요약도 해보기로 했습니다. 자세히 읽지는 않았으니 정확하지 않거나 핵심이 아닌 부분이 있을 수도 있고, 모든 딥러닝의 주요 논문이 있지도 않습니다. 혹시 공부하시다가 놓친 부분을 제 글에서 다시 잡으실 수라도 있으면 저는 뿌듯하겠습니다.
두번째 글은 BiRNN, LSTM, Skip-gram, Word2Vec과 같은, Attention과 Transformer 등장 이전의 자연어처리에 대한 논문들입니다. Seq2Seq과 Attention 등 둘 이상의 언어를 pre-training하고 fine-tuning하는 내용은 다음 포스팅을 봐주세요. 머신러닝이나 딥러닝 기초를 학습하시고 싶은 분들은 단단한 머신러닝 또는 심층 학습 같은 교과서를 먼저 읽고 오시면 좋습니다.
1. BiRNN (Bidirectional Recurrent Neural Network)
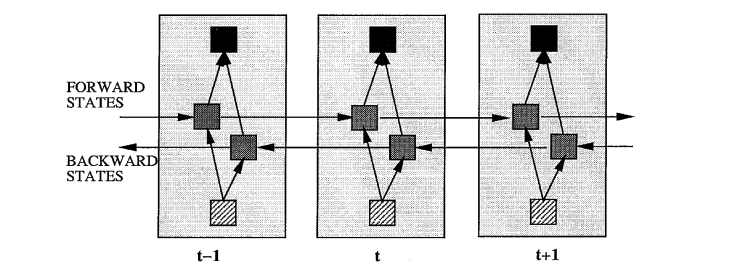
- Schuster, M., & Paliwal, K. K. (1997). Bidirectional recurrent neural networks. IEEE transactions on Signal Processing, 45(11), 2673-2681.
- 부식돼서 논문읽기조차 쉽지 않은 RNN(recurrent neural network) 알고리즘의 강화판.
- 기존의 RNN에서 사용하던 forward network에 backward를 더해 양방향 RNN을 만듦.
- 뒤에서 업데이트된 값으로 앞을 다시 업데이트하므로 오차(MSE)가 적어질 수 있다는 발상.
2. LSTM (Long Short-Term Memory)

- Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural computation, 9(8), 1735-1780.
- Graves, A. (2013). Generating sequences with recurrent neural networks. arXiv preprint arXiv:1308.0850.
- 원논문이 좀 많이 어렵긴 한데… 애초에 모델 자체가 단순하진 않음. 2013년 응용논문은 읽기 쉬움.
- 기존 RNN에서 각 단계의 가중치를 가져오긴 하지만, output vector만 계속 전달하니 기억이 소실됨.
- 각 단계에 memory cell을 도입해서 복잡한 연산을 수행함.
- 일단 해당 단계의 input이 해당 단계 가중치가 곱해진 채로 memory cell로 들어옴.
- 기존 RNN처럼 전 단계에서 받아온 가중치를 곱해주면서, 전 단계 cell의 가중치 정보를 첨가함.
- 기존 RNN과 달리, 전 단계에서 추가로 가중치를 받아와 곱해줌. 이 가중치가 memory.
- 여기까지만 계산 완료된 결과를 해당 cell의 memory로 간주해 다음 cell로 넘김.
- 또는 후처리를 하든지 해서 output으로 내보내거나 다음 cell 가중치으로 넘김.
- 들어오는 벡터(3): 해당 cell input, 전 cell output, 전 cell memory.
- 나가는 벡터(3)
- 해당 cell memory(1) → 다음 cell memory로 전달.
- 해당 cell output(2) → 다음 cell output으로 전달되거나 해당 cell output으로 출력.
- 2013년까지 가서는 더욱 발전해서, forget gate가 별도로 cell memory 후처리를 함.
- BiLSTM - Huang, Z., Xu, W., & Yu, K. (2015). Bidirectional LSTM-CRF models for sequence tagging. arXiv preprint arXiv:1508.01991. 참고.
3. CBOW & Skip-gram
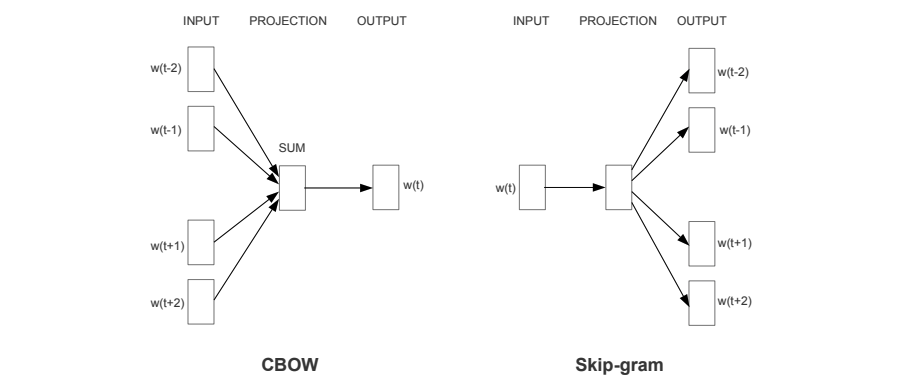
- Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781.
- "… it was shown for example that vector('King') - vector('Man') + vector('Woman') results in a vector that is closest to the vector representation of the word Queen."
- N-gram: 문장을 단어 N개 길이의 window로 잘라서 생각하는 기존 방식.
- 당연히 모든 domain data context를 다 고려해줄 수 없는 한계가 있었음.
- 단어를 vector space 위에 띄워 서로 유사성을 계산할 수 있게끔 하는 것이 나음.
- CBOW(continuous bag-of-words): 문서 내 단어 각각을 one-hot vector로 만든 뒤, 문장 앞뒤 N개의 단어가 가중치 벡터를 통과한 뒤의 벡터와 중앙 단어의 벡터 사이 엔트로피 차이를 가중치 업데이트.
- Skip-gram: 문서 내 단어 각각을 one-hot vector로 만든 뒤, 각 단어가 앞뒤 N개의 위치 각각의 가중치 벡터를 통과한 뒤의 벡터와 각 위치의 실제 단어의 벡터 사이 엔트로피 차이를 가중치 업데이트.
- 실제로 해보니 Skip-gram 방식이 위와 같이 유의어를 예측 가능한 벡터를 잘 만드는 것을 확인함.
4. Word2Vec

- Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., & Dean, J. (2013). Distributed representations of words and phrases and their compositionality. Advances in neural information processing systems, 26.
- "It is considered to have been answered correctly if the nearest representation to vec('Montreal Canadiens') - vec('Montreal') + vec('Toronto') is vec('Toronto Maple Leafs')."
- Skip-gram을 발전시켜 이제 의미를 가지는 어구를 통째로 벡터화시켜보고자 함.
- Hierarchical softmax: 앞뒤 N개 단어의 벡터를 binary tree 위에 올려 확률을 조건부로 계산.
- Negative sampling: Negative 관계인 단어는 일부만 sampling해서 확률을 업데이트하는 방식.
- Subsampling frequent words: 자주 등장하는 “the” 같은 단어는 빈도에 따라 제외함.
- Sampling을 개선한 이번 모델이 hierarchical softmax를 활용했던 연구보다 더 좋은 효과를 보임.
'과학 > 머신러닝' 카테고리의 다른 글
| 딥러닝 주요 논문 리뷰 (4) - 이미지 생성 (0) | 2022.12.17 |
|---|---|
| 딥러닝 주요 논문 리뷰 (3) - 이미지 (0) | 2022.12.10 |
| 딥러닝 주요 논문 리뷰 (2) - 자연어 생성 (0) | 2022.12.04 |
| 딥러닝 주요 논문 리뷰 (0) - 기초 (0) | 2022.11.21 |




댓글